4 Arithmetic: Computing Numbers
4.1 Refining the Amount Language
We have seen all the essential pieces of a language (a grammar, operational semantics, an interpreter, and some correctness tests) for implementing a programming language, although for a very simple one.
We will now, through the process of iterative refinement grow the language to be more useful by designing more features.
We will add arithmetic operations to Amount, such that we can now increment, decrement numbers as well as do arithmetic operations such as addition, subtraction, multiplication, and division. We will call this new language Arithmetic. It is still a very simple language, but at least our programs will compute something.
4.2 Syntax for Arithmetic
Arithmetic extends Amount to have some unary and binary operations. It contains the #lang racket line followed by a single expression. The grammar of concrete expressions is:
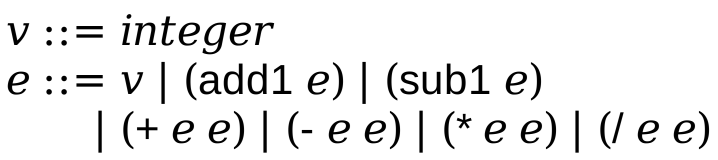
So 42, -8, 120 are all valid programs now. But so are programs like (add1 42), (+ 43 (add1 23)).
An example of a concrete program:
#lang racket (+ 43 (- (add1 23) (sub1 -8)))
4.3 Meaning of Arithmetic Programs
The meaning of Arithmetic programs depends of the form of the expression:
The meaning of the integer literal is the just the integer itself;
The meaning of the the increment expression (add1) is one more than the subexpression;
The meaning of the the decrement expression (sub1) is one less than the subexpression;
The meaning of the the addition expression (+) is the sum of two subexpressions;
The meaning of the the subtraction expression (-) is the difference between the first and second subexpressions;
The meaning of the the multiplication expression (*) is the product of the two subexpressions;
The meaning of the the division expression (/) is the result of dividing the first subexpression by the second.
Note, that Arithmetic is a language of integers, hence all operations should evaluate to integers.
The operational semantics reflects the dependence of the subexpressions as well.
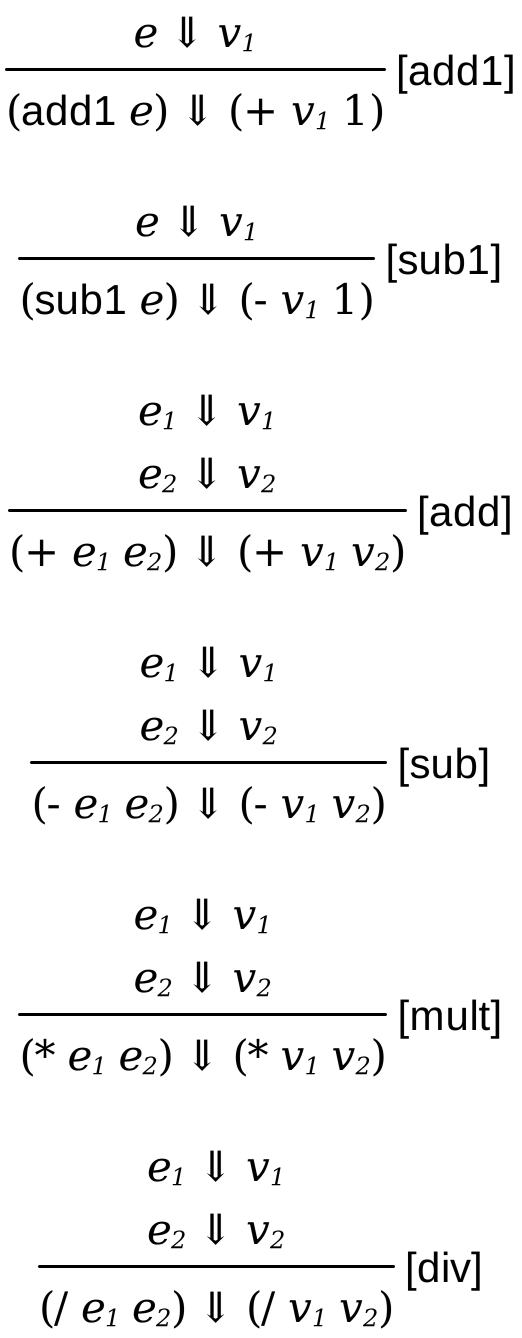
The rule for values is omitted; it’s the exact semantics of integers from Amount: A Language of Numbers.
The meaning of the increment (add1) and decrement (sub1)operations depend on only one subexpression. In particular they have premises over the line. If the premise is true, the conclusion below the line is true as well. These rules are conditional on the premise being true. In contrast, the rule for values applies unconditionally.
Similarly, the addition (+) operation depends on two subexpressions. The rules for -, *, and / all look similar.
Recall that  is a relation. So we can say:
is a relation. So we can say:
For all integers v, v is in
 ;
;For all expressions e and integers v, if (e, i) is in
 then ((add1 e), (+ v 1)) is in
then ((add1 e), (+ v 1)) is in  ;
;For all expressions e1, e2 and integers v1 and v2, if (e1, v1) and (e2, v2) are in
 then ((+ e1 e2), (+ v1 v2)) is in
then ((+ e1 e2), (+ v1 v2)) is in  ;
;... and so on!
These rules are inductive. We start from the meaning of integers and if we have the meaning of an expression, we can construct the meaning of a larger expression.
4.4 Interpreter for Arithmetic
We can translate these operational semantics rules to an interpreter:
#lang racket (require rackunit) (provide interp) ;; Expr -> Integer ;; Interpret given expression (define (interp e) (match e [(? integer?) e] [`(add1 ,e) (+ (interp e) 1)] [`(sub1 ,e) (- (interp e) 1)] [`(+ ,e1 ,e2) (+ (interp e1) (interp e2))] [`(- ,e1 ,e2) (- (interp e1) (interp e2))] [`(* ,e1 ,e2) (* (interp e1) (interp e2))] [`(/ ,e1 ,e2) (/ (interp e1) (interp e2))]))
> (interp 42) 42
> (interp -8) -8
> (interp '(add1 30)) 31
> (interp '(* 2 3)) 6
> (interp '(+ 43 (add1 23))) 67
Here’s how to connect the dots between the semantics and interpreter: the interpreter is computing, for a given expression e, the integer v, such that (e, v) is in  . The interpreter uses pattern matching to determine the form of the expression, which determines which rule of the semantics applies.
. The interpreter uses pattern matching to determine the form of the expression, which determines which rule of the semantics applies.
if e is an integer v, then we’re done: this is the right-hand-side of the pair (e, v) in
 .
.if e is an expression (add1 e), then we recursively use the interpreter to compute v such that (e, v) is in
 . But now we can compute the right-hand-side by adding 1 to i.
. But now we can compute the right-hand-side by adding 1 to i.if e1 and e2 are expressions (+ e1 e2), then we recursively use the interpreter to compute v1 and v2 such that (e1, v1) and (e2, v2) are in
 . But now we can compute the right-hand-side by adding v1 to v2.
. But now we can compute the right-hand-side by adding v1 to v2.... and so on!
This explanation of the correspondence is essentially a proof by induction of the interpreter’s correctness.
You can build up a step-by-step proof using the  relation to show that some expression indeed does evaluate to the value produced by the interpreter. All you have to do is use the above formal rules to derive a proof that the relation holds for the expression and the expected value. For example, the proof that (+ 43 (- (add1 23) (sub1 -8))) evaluates to 76 will be:
relation to show that some expression indeed does evaluate to the value produced by the interpreter. All you have to do is use the above formal rules to derive a proof that the relation holds for the expression and the expected value. For example, the proof that (+ 43 (- (add1 23) (sub1 -8))) evaluates to 76 will be:

Notice how application of each rule creates subgoals? We recursively apply any available rule until we reach the value rule. The value rule always concludes a subgoal to be proved because it does not depend on any other facts to be true. We discuss this further in Formal Semantics.
We can now define the correctness of our interpreter:
Interpreter Correctness: For all expressions e and integers v, if e  v, then the interpreter (interp e) equals v.
v, then the interpreter (interp e) equals v.
4.5 Correctness
We can turn the examples we have above into automatic test cases to verify our interpreter is correct. We will reuse the check-interp function from Amount: A Language of Numbers.
> (define (check-interp e) (check-eqv? (interp e) (eval e)))
To turn this into an automatic test case:
> (check-interp 42) > (check-interp -8) > (check-interp '(add1 30)) > (check-interp '(* 2 3)) > (check-interp '(+ 43 (add1 23)))
The problem, however, is that generating random Arithmetic programs is less obvious compared to generating random Amount programs (i.e. random integers). Randomly generating programs for testing is its own well studied and active research area. To side-step this wrinkle, here is a small utility for generating random Amount programs, which you can use, without needing the understand how it was implemented. Don’t worry, you will not be asked to write programs like this in the exam or assignments.
> (define (random-expr) (contract-random-generate (flat-rec-contract b (list/c 'add1 b) (list/c 'sub1 b) (list/c '+ b b) (list/c '- b b) (list/c '* b b) (list/c '/ b b) (integer-in #f #f))))
Calling (random-expr) now will produce random programs from our grammar:
> (random-expr)
'(*
(/ (/ (/ -1 0) (* -4 0)) -1)
(/ (sub1 (add1 4)) (+ 4 (add1 -5))))
> (random-expr)
'(*
(/ (- (- -4 -5) (* -3 5)) (+ (sub1 2) (sub1 1)))
-1)
> (random-expr)
'(*
(/ (sub1 (- -19 4)) (/ (add1 -1) (/ 3 -2)))
16)
> (random-expr) -1
You can run this in a loop to check if our Arithmetic language interpreter complies with Racket semantics:
> (for ([i (in-range 100)]) (check-interp (random-expr)))
--------------------
ERROR
name: check-eqv?
location: eval:23:0
/: division by zero
--------------------
--------------------
ERROR
name: check-eqv?
location: eval:23:0
/: division by zero
--------------------
--------------------
ERROR
name: check-eqv?
location: eval:23:0
/: division by zero
--------------------
--------------------
ERROR
name: check-eqv?
location: eval:23:0
/: division by zero
--------------------
--------------------
ERROR
name: check-eqv?
location: eval:23:0
/: division by zero
--------------------
--------------------
ERROR
name: check-eqv?
location: eval:23:0
/: division by zero
--------------------
We see a bunch of failures because of division by 0, which we did not handle in our language semantics nor our interpreter. We will revisit this again when we look at how to handle errors in Defend: Handling Errors.
At this point can we find any other counter-example to interpreter correctness that is not division by 0? It’s tempting to declare victory. But... can you think of a valid input (i.e. some program) that might refute the correctness claim?
Think on it.
4.6 Does our language always produce integers?
Values in our language are integers only. However, does our language always produce integers? Let us try this with a very simple program:
> (interp '(/ 5 3)) 5/3
Why is it returning values as a fraction? Fractions are not a part of our language! Fractions, or more generally, rational numbers are defined in Racket.
> (/ 5 3) 5/3
Our language Arithmetic looks like Racket, but has different semantics, primarily because our language only has integers. What we are seeing is the bubbling up semantics of Racket, our source language, into Arithmetic, our target language. This is a common problem in language design: the semantics of your source language will tend to show up in your target language and as a language designer you have to be careful about such cases! For example, Python is implemented in C, but Python supports arbitrary sized integers, whereas C is only limited machine-sized integers. Python developers have to be careful to ensure that C numerics behavior does not show up in Python.
Thankfully, our language Arithmetic is very simple. To fix this, we only have to update the division of two integers to return their quotient.
#lang racket (require rackunit) (provide interp) ;; Expr -> Integer ;; Interpret given expression (define (interp e) (match e [(? integer?) e] [`(add1 ,e) (+ (interp e) 1)] [`(sub1 ,e) (- (interp e) 1)] [`(+ ,e1 ,e2) (+ (interp e1) (interp e2))] [`(- ,e1 ,e2) (- (interp e1) (interp e2))] [`(* ,e1 ,e2) (* (interp e1) (interp e2))] [`(/ ,e1 ,e2) (quotient (interp e1) (interp e2))]))
This fixes the semantics of our language:
> (interp '(/ 4 2)) 2
> (interp '(/ 5 3)) 1